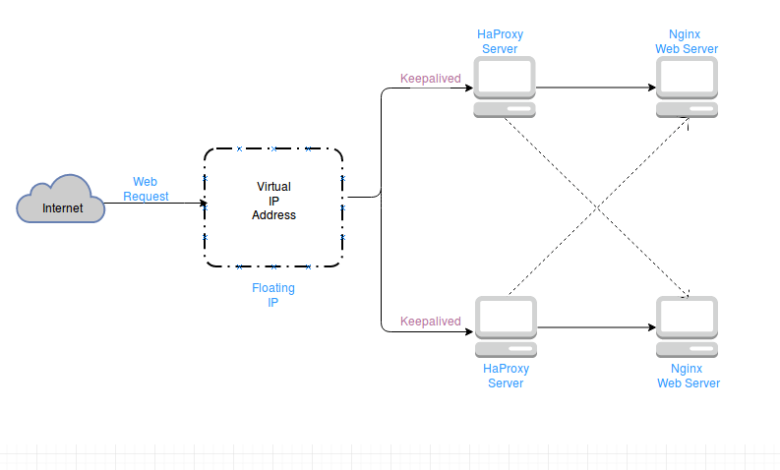
High availability (HA) is a critical requirement for modern IT infrastructure, ensuring that systems remain operational and accessible even in the event of hardware failures, software crashes, or other disruptions. Configuring a Linux server for high availability involves setting up redundancy, failover mechanisms, and monitoring to minimize downtime and maintain service continuity.
This guide will walk you through the steps to configure a Linux server for high availability, covering key concepts, tools, and best practices.
Table of Contents
- Introduction to High Availability
- Key Components of High Availability
- Redundancy
- Failover
- Load Balancing
- Monitoring and Automation
- Planning Your High Availability Setup
- Identifying Critical Services
- Choosing the Right Tools
- Network and Hardware Considerations
- Configuring Redundancy
- Setting Up RAID
- Configuring Network Bonding
- Implementing Failover with Pacemaker and Corosync
- Installing Pacemaker and Corosync
- Configuring Resource Agents
- Testing Failover
- Load Balancing with HAProxy
- Installing HAProxy
- Configuring Load Balancing
- Monitoring Load Balancer Performance
- Setting Up Monitoring and Automation
- Using Nagios for Monitoring
- Automating Failover with Scripts
- Best Practices for High Availability
- Conclusion
1. Introduction to High Availability
High availability refers to the design and implementation of systems that ensure minimal downtime and continuous operation. In a high availability setup, redundant components and failover mechanisms are used to provide seamless service even during failures.
Key goals of high availability include:
- Minimizing Downtime: Ensuring that services remain accessible even during maintenance or failures.
- Data Integrity: Preventing data loss during failover or recovery.
- Scalability: Allowing the system to handle increased load without degradation in performance.
2. Key Components of High Availability
Redundancy
Redundancy involves duplicating critical components (e.g., servers, storage, network connections) to ensure that a backup is available if the primary component fails.
Failover
Failover is the process of automatically switching to a redundant or standby system when the primary system fails. This ensures continuous service availability.
Load Balancing
Load balancing distributes incoming network traffic across multiple servers to ensure no single server is overwhelmed, improving performance and reliability.
Monitoring and Automation
Monitoring tools track the health and performance of systems, while automation ensures that failover and recovery processes are executed without manual intervention.
3. Planning Your High Availability Setup
Identifying Critical Services
Determine which services (e.g., web servers, databases, file storage) are critical for your infrastructure and require high availability.
Choosing the Right Tools
Select tools and technologies that align with your HA goals. Common tools include:
- Pacemaker and Corosync: For failover and cluster management.
- HAProxy: For load balancing.
- Nagios: For monitoring.
Network and Hardware Considerations
Ensure that your network and hardware infrastructure supports redundancy and failover. This includes:
- Redundant power supplies.
- Multiple network interfaces.
- High-speed, reliable storage (e.g., SSDs).
4. Configuring Redundancy
Setting Up RAID
RAID (Redundant Array of Independent Disks) provides redundancy for storage. Common RAID levels include:
- RAID 1: Mirroring (duplicates data across two disks).
- RAID 5: Striping with parity (distributes data and parity across three or more disks).
To set up RAID on Linux:
- Install the
mdadmtool:sudo apt install mdadm
- Create a RAID array:
sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1
- Format and mount the RAID array:
sudo mkfs.ext4 /dev/md0 sudo mount /dev/md0 /mnt/raid
Configuring Network Bonding
Network bonding combines multiple network interfaces into a single logical interface for redundancy and increased bandwidth.
- Install the
ifenslavepackage:sudo apt install ifenslave
- Edit the network configuration file (
/etc/network/interfaces):auto bond0 iface bond0 inet dhcp bond-mode active-backup bond-miimon 100 bond-slaves eth0 eth1 - Restart the networking service:
sudo systemctl restart networking
5. Implementing Failover with Pacemaker and Corosync
Installing Pacemaker and Corosync
Pacemaker and Corosync are used to manage failover in a cluster.
- Install the packages:
sudo apt install pacemaker corosync pcs
- Start and enable the services:
sudo systemctl start pacemaker corosync sudo systemctl enable pacemaker corosync
Configuring Resource Agents
Resource agents manage services (e.g., Apache, MySQL) in the cluster.
- Add a resource (e.g., an IP address):
sudo pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.1.100 cidr_netmask=24 op monitor interval=30s
- Add a service (e.g., Apache):
sudo pcs resource create WebServer ocf:heartbeat:apache configfile=/etc/apache2/apache2.conf op monitor interval=30s
Testing Failover
Simulate a failure by stopping a service or shutting down a node. Verify that the resources fail over to the standby node.
6. Load Balancing with HAProxy
Installing HAProxy
- Install HAProxy:
sudo apt install haproxy
- Start and enable the service:
sudo systemctl start haproxy sudo systemctl enable haproxy
Configuring Load Balancing
Edit the HAProxy configuration file (/etc/haproxy/haproxy.cfg):
frontend http_front
bind *:80
default_backend http_back
backend http_back
balance roundrobin
server web1 192.168.1.101:80 check
server web2 192.168.1.102:80 check
Monitoring Load Balancer Performance
Use the HAProxy stats page to monitor performance:
listen stats
bind *:8080
stats enable
stats uri /stats
stats auth admin:password
7. Setting Up Monitoring and Automation
Using Nagios for Monitoring
- Install Nagios:
sudo apt install nagios4
- Configure Nagios to monitor your servers and services.
Automating Failover with Scripts
Write custom scripts to automate failover and recovery processes. For example, a script could detect a failed service and restart it on another node.
8. Best Practices for High Availability
- Regular Testing: Test your HA setup regularly to ensure it works as expected.
- Documentation: Maintain detailed documentation of your HA configuration and procedures.
- Backup and Recovery: Implement robust backup and recovery strategies to protect against data loss.
- Scalability: Design your HA setup to scale as your infrastructure grows.
9. Conclusion
Configuring a Linux server for high availability is a complex but essential task for ensuring continuous operation and minimizing downtime. By following this guide, you can set up redundancy, failover, load balancing, and monitoring to create a robust and reliable HA infrastructure. Whether you’re managing a small business or a large enterprise, high availability is key to maintaining service continuity and meeting user expectations.
Happy configuring!